Mpe 3 an Ordered List of Specific Records and Specific Fields Printed in an Easytoread
JMESPath Filtering
premium
In most cases, you can use API Connector's visual field editor to easily select the fields you'd like to see in your sheet. However, if you're interested in more powerful filtering capabilities, read ahead for information on using JMESPath expressions in your requests.
Contents
- Why Filter Responses?
- Before You Begin
- Get Your JSON
- Quick JSON Overview
- General Syntax
- Example 1: Query for Specific Fields
- Example 2: Query Nested Fields
- Example 3: Query Two or More Top-Level Elements
- Example 4: Convert Column Keys into Field Headers
- Tips
- Troubleshooting
- JMESPath Info & Expression Tester
Why Filter Responses?
- change the report structure, for example to convert columns to rows
- filter for certain fields or values in the response data
- simplify reporting by requesting only the data you need
Before You Begin
If you haven't already, click here to install the API Connector add-on from the Google Marketplace.
Get Your JSON
The first step of working with JMESPath is to view the JSON output of your API request.
To view the raw JSON, set up and save your request, and then click Output options > JMESPath > Preview API response. This will display the JSON response in a modal where you can copy or download it.
This article contains more information on previewing API responses: https://mixedanalytics.com/knowledge-base/preview-api-response/
Quick JSON Overview
If you already know about JSON, you can skip right past this section. JSON is a data format made up of objects and arrays, and we have to identify these structures to create JMESPath expressions.
- Objects are unordered collections of name/value pairs. They start and end with curly braces.
{"wrapperType": "track", "kind": "song", "artistId": 657515} - Arrays are ordered lists of values. They start and end with square brackets. Arrays can contain lists of objects, like this:
"results": [ { "artistName": "Radiohead", "collectionName": "In Rainbows", "trackName": "Weird Fishes / Arpeggi"}, { "artistName": "Radiohead", "collectionName": "In Rainbows", "trackName": "15 Step"} ] If you aren't used to JSON yet, all you really need to know for now is if you see [] it's an array, and if you see {} it's an object.
General Syntax
The full JMESPath specification is a powerful but complex query language, so this article will focus only on the most common use case for API Connector: choosing which fields to print into your spreadsheet.
When we choose those fields, we need to identify the exact path to their location, where paths to values in arrays take the format array_name[].field and paths to values in objects take the format object_name.field.
The general syntax for setting up a JMESPath expression is like this, where we first provide a new key (name) for the field and then provide the path to that field:
array_name[].{new_key1:path1, new_key2:path2} Examples are right below.
Example 1: Query for Specific Fields
In this example, we'll request the collectionName and trackName fields from an example JSON response.
{ "resultCount": 2, "results": [ { "wrapperType": "track", "kind": "song", "artistId": 657515, "collectionId": 1109714933, "trackId": 1109715168, "artistName": "Radiohead", "collectionName": "In Rainbows", "trackName": "Weird Fishes / Arpeggi" } ] } By checking the JSON, we can see that trackName and collectionName are located inside the results array, such that our JMESPath expression looks like this. We'll give them new names to demonstrate how that works:
results[].{"Track names":trackName,"Collection names":collectionName} We need quotation marks around the new names because they contain a space (otherwise just enter them directly). Enter this into API Connector like this:

This will result in the following output:

Example 2: Query Nested Fields
In some cases, values may be nested inside other objects and arrays. As mentioned above we need to recognize the data structure to identify the path. In this next example, "data" is an array, while "billing_details" is an object.
{ "data": [{ "id": "1234567", "object": "charge", "amount": 100, "billing_details": { "email": "[email protected]", "name": "Apple Appleby" } }] } To retrieve the amount and the email address, we'd set our query like this, since fields nested within objects are identified with a dot:
data[].{amount:amount,billing_email:billing_details.email} Fields nested within arrays are accessed with [], so if you instead had, say, a product ID nested within a "products" array, you'd create an expression like this:
orders[].{order_id:order_id, product_id:products[].id} Example 3: Query Two or More Top-Level Elements
I'm giving this its own section because it took me forever to figure out — and then it turned out the answer is very simple.
You may come across some JSON like this, where you want elements from two different top-level objects or arrays. For example, in this example JSON block you may want to get the number of records from the pagination object as well as date information from within the data array.
{ "pagination": { "limit": 100, "offset": 0, "count": 100, "total": 5000 }, "data": [ { "date": "2020-06-08", "status": "scheduled", "timezone": "America/New_York" }] } To grab elements from both the pagination object and the data array at the same time, either of the following structures will work. You may find that one or the other provides a more convenient output for your data set.
{pagination_total:pagination.total,data:data[].{date:date,timezone:timezone}} [{pagination_total:pagination.total},data[].{date:date,timezone:timezone}] Example 4: Convert Column Keys into Field Headers
API Connector now has a native option to flatten column keys into field headers without requiring JMESPath: Flatten Fields to Columns. The JMESPath below is still presented for reference.
You may encounter an inconvenient pattern where key-value pairs are listed within a parent header, like this:
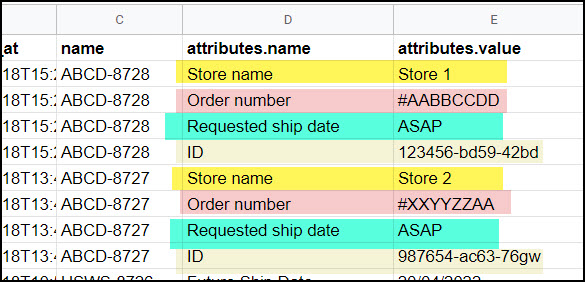
In this example, we have multiple keys like "Store name" and "Order number" grouped together under attributes.name, which makes the data hard to work with.
We can use JMESPath to restructure this such that each key gets its own column. To do so use this pattern to extract the keys:
{store_name:attributes[?name=='Store name']|[0].value, order_number:attributes[?name=='Order number']|[0].value, requested_ship_date:attributes[?name=='Requested ship date']|[0].value, ID:attributes[?name=='ID']|[0].value } In words, each line is saying something like this: take the value of the attribute named 'Store name', and give it a field header of store_name .
This will result in a flattened output like this:

Tips
- If you are working with deeply nested or complicated JSON, it might be hard to visually recognize the path to your desired fields. In those cases it usually helps to use a JSON navigator. I like this one: https://jsoneditoronline.org/.
- You can reference cell values in your JMESPath expression. One example use case would be using a Sheets function like =MAX to find the maximum date in a column, then using that cell value as part of a JMESPath filter to filter for new data only.
Troubleshooting
- In the case that your JSON keys start with a number or contain dashes or spaces, you'll need to enclose them in quotes, e.g.
"123"[].{order_id:order_id}. - If you enter an invalid JMESPath expression you may see error messages like "Request failed: Server response not in JSON, XML, or CSV format" or "Expected argument of type object, but instead had type X". To address, make sure your JMESPath is correct and returns a valid JSON object (e.g. if you have a field named ID, add a JMESPath query of
{id:id}rather than simplyid). - [Advanced] When you filter responses, pay attention to small differences in your JMESPath syntax. The following two expressions will yield almost the same result, as both expressions produce a column of dates and a column of time zones. However they have an important difference:
- This first expression evaluates each dataset separately. This means that any missing or null values will be ignored, such that populated data shifts up into the first open cell, and the two data sets may not match up across columns:
{date:data[].date,timezone:data[].timezone} - This second expression will evaluate the entire data array, and keep these elements synced between columns. Therefore this is almost always the better option:
data[].{date:date,timezone:timezone}
- This first expression evaluates each dataset separately. This means that any missing or null values will be ignored, such that populated data shifts up into the first open cell, and the two data sets may not match up across columns:
- [Advanced] In some cases, you'll find that an expression like
properties[].{field1:field1,field2:field2}doesn't always produce new fields for field1 and field2, resulting in mismatched columns. This can happen when the array ("properties" in this example) is not consistently populated, since the expression doesn't work on a completely empty array. To resolve, modify the expression like this:properties[].{field1:field1,field2:field2} || {field1:"",field2:""}. - [Advanced] Occasionally you may run into JSON constructed of only objects. This is an undesirable data structure as it prevents API Connector from determining which data points should be returned as rows vs. columns (it typically results in all data on a single row, with a new column header for each element). In those cases, one option is to convert the data into a more useful structure with the
values(@)function, e.g.Data.values(@)if Data is the name of the parent object.
JMESPath Info & Expression Tester
You may use any features of the JMESPath query language for JSON. Check the tutorial for additional methods of retrieving specific values from JSON: https://jmespath.org/tutorial.html
If you would like to test your JMESPath syntax, you can paste over the JSON examples in the tutorial and enter your own query into the input field, like this:

Source: https://mixedanalytics.com/knowledge-base/filter-specific-fields-values/
0 Response to "Mpe 3 an Ordered List of Specific Records and Specific Fields Printed in an Easytoread"
Post a Comment